CLUSTERED INDEX VS NON CLUSTERED INDEX

Clustered Index
- Only one clustered index can be there in a table because of the sorted order
- Sort the records and store them physically according to the order
- Data retrieval is faster than non-clustered indexes
- Do not need extra space to store logical structure
- A primary key by default creates a clustered index on it.
Non Clustered Index
- There can be any number of non-clustered indexes in a table because of the number of unique keys we can create.
- Do not affect the physical order. Create a logical order for data rows and use pointers to physical data files
- Data insertion/update is faster than clustered index
- Use extra space to store logical structure
- A unique key/keys by dafault created an unclustered index on it.
In Depth Explanation:
Clustered
Technically speaking, a clustered index is a B-Tree data structure where all the rows in a table are stored at the leaf level of the index. In other words, a clustered index not only includes the root level and intermediate level index pages found in B-Tree indexes, it also includes all the data pages that contain every row in the entire table. In addition, the rows in a clustered table are logically ordered by the key selected for the clustered index (unlike a heap whose rows and pages are unordered). Because of this, a table can only have one clustered index.
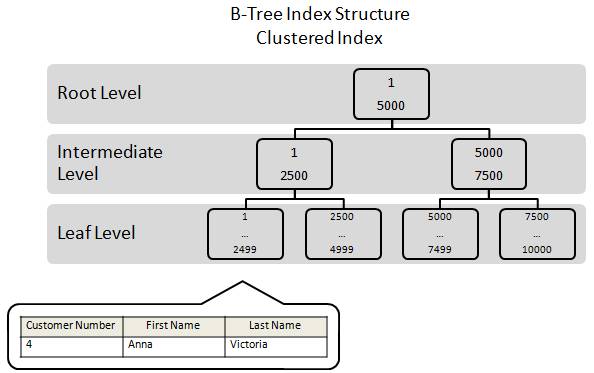
In a clustered index, the index and the data are one in the same. Rows are stored as the leaf pages of a clustered index.
For example, let’s say that we have a table called “Customers” that includes three columns: Customer Number, First Name, and Last Name, and that the key for the clustered index is based on the Customer Number column.
Because this table has a clustered index, the entire row would be stored on a data page as part of the leaf level of the B-Tree index. This is shown in above figure , where we see that a particular row from that table is physically stored on the leaf level page that begins with the letter “1.” This page also holds additional rows, but they are not shown here in this illustration in order to keep the example as simple as possible.
Because a clustered index is both an index and the rows of the table, whenever you execute a query against the data using the key column as your selection criteria, you can quickly return the data because the data is part of the index. All the query has to do is transverse the index until it finds the row data stored at the leaf level, and return it.
Non-Clustered
Like a clustered index, a non-clustered index is a B-Tree data structure (although it is a separate data structure from the clustered index). The main difference between the two is that while a clustered index includes all of the data of a table at the leaf level, a non-clustered index does not. Instead, at the leaf level, a non-clustered index includes the key value and a bookmark (pointer) that tells SQL Server where to find the actual row in the clustered index.
Let’s take a brief look at how a non-clustered index works. In this example, we are going expand upon our previous example of a Customer table that has three columns: Customer Number, First Name, and Last Name. As in our previous example, we are going to have a clustered index that uses the Customer Number as its key. In addition, we are going to add a non-clustered index on the Last Name column. Given this, let’s say we want to return all the rows (and all the row’s columns) in the Customer Table that have a last name of “Victoria”, and that we want to use the non-clustered index on the Last Name column to quickly find and return the data.
Here’s what happens at the index level. See the below figure
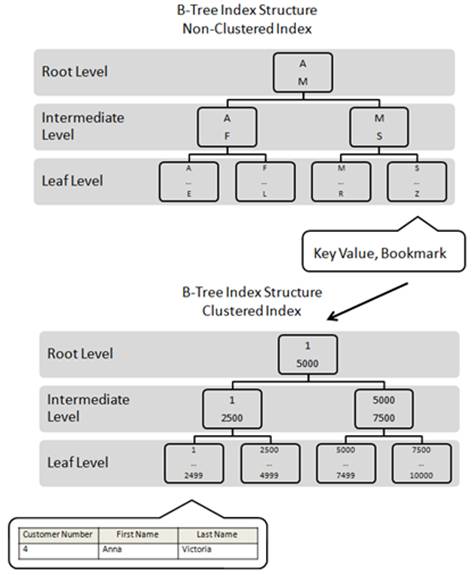
Figure 2: A non-clustered index must often work with a clustered index in order for all the selected data to be returned by a query.
The first step in retrieving all of the rows with a Last Name of “Victoria” is to use the non-clustered index on the Last Name column to identify any rows that match. To find the rows, SQL Server begins at the root level of the non-clustered index, looking for any matching rows. The root page is scanned and two rows are found: an “A” and an “M”. Each of these rows points to different pages in the intermediate level. The first letter of “Victoria” is “V”, but there is no row in the root level page that begins with the letter “V”. But since this index is in alphabetical order, we know that “V” follows “M”. So, to find the letter “V”, we must transverse to the intermediate level to further narrow our search. As you can see in figure 2, the letter “M” points to an index page in the intermediate level that starts with the letter “M”.
When we go to the intermediate level and look at the index page that begins with the letter “M”, notice that it only has two records: an “M” and an “S”. Notice that the letter “V” is still nowhere to be found. Since we can’t find the letter “V” on this index page, we need to transverse to the leaf level and see if we can find it there.
Once we get to the leaf level page that begins with “S”, we now identify all the rows on that page that begin with “V”. Each row that begins with “V” is then compared to the last name “Victoria”. In our case, there is a single match. The last name “Victoria” is found in the Last Name non-clustered index key. Now we know that a row does exist that meets our selection criteria, the problem is that all of the data for that row (Customer Number, First Name, and Last Name) aren’t stored at the leaf level. Instead, the only data stored at the leaf level is the key “Victoria” and a bookmark that points to the corresponding record in the table-which as we know-is a clustered index. In this example, the bookmark correspondents with the Customer Number “4”.
Now that SQL Server knows that a row does exist, and that it exists in the clustered index as Customer Number 4, the actual contents of the row (the three columns) must be retrieved. So next, SQL Server must take the bookmark value, the number “4”, and then start at the root level of the clustered index, and then transverse the intermediate and leaf level until it locates the matching row. At this point, the data is returned back the original query. See figure 2.
As you can see, using a non-clustered index with a clustered index can be somewhat complex than using a clustered index alone. But in the end, it is often much faster to retrieve rows from a table this way than by scanning each one of them, one row at a time.



Comments
Post a Comment